I don’t ever like to feel that I am wasting a client’s time by doing unnecessary load tests, but a long time ago I had an experience that altered my definition of what a necessary test is.
I had come to this project after the scope had been decided and the Detailed Test Plan had been written. The overall system was made up of four applications; privately I queried why we were bothering to test ApplicationX, which was an exceedingly low volume application.
ApplicationX was not business-critical or customer-facing. It was performing acceptably with a production-sized dataset and a small number of test users. Its functionality was unlikely to put significant load on the system, and there would be a maximum of 6 concurrent users in Production. Not load testing ApplicationX seemed like a perfect way to save some time.
Fortunately the Test Manager wanted to stick with the original plan (rather than having to get sign-off on an amended plan), because I was very very very wrong.
Here’s a graph of what happened as I slowly ramped up my virtual users…
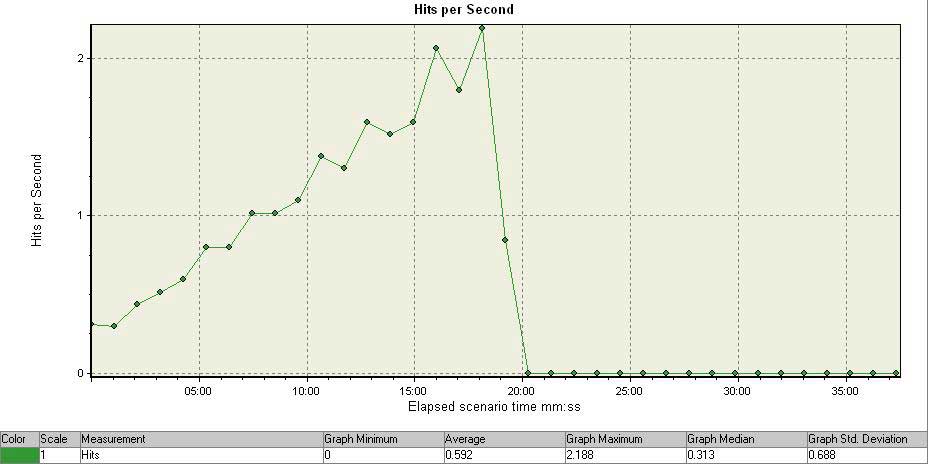
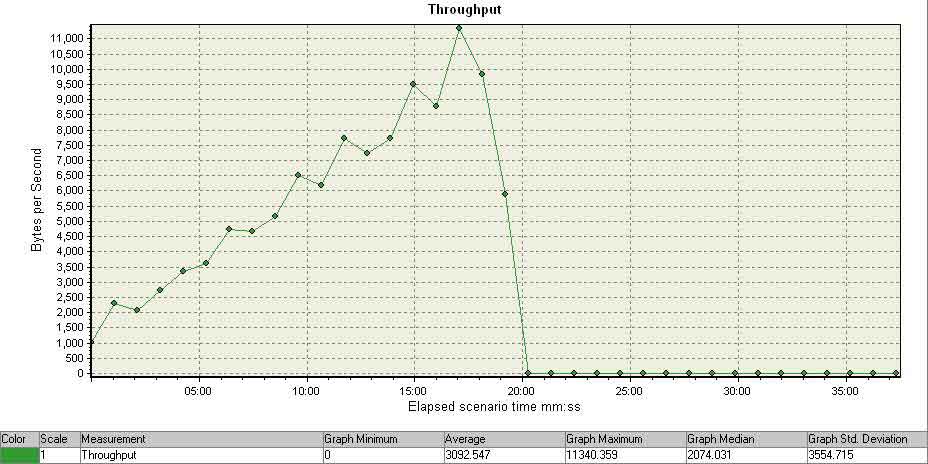
I had never seen a web application fall over under a load of only two hits per second before. I didn’t think it was possible. My grandmother could handle two hits per second creating HTTP headers on a typewriter and sending the packets via carrier pigeon.
The worst part of this was that ApplicationX was running in the same JVM as an application that was business critical, so when it went down, it brought the other system down with it. A severity-3 defect suddenly became a severity-1 “oh my god, we can’t do business” defect.
So, the lesson I took away from that experience was that even if an application is not necessarily a candidate for load testing, but it shares infrastructure components with an application that is business-critical, then it is a good idea to consider at least some rudimentary sociability testing under load to shake out any really nasty problems like this one.
Related Posts



6 Comments
Comments are closed.
“My grandmother could handle two hits per second creating HTTP headers on a typewriter and sending the packets via carrier pigeon.”
LMAO! 😉
Something I didn’t add to the above post was that the “falling over under low load” problem happened even when the two hits per second were for static content with small file sizes – such as small gifs.
The web server that was running inside the JVM with the other application was Jetty, a mature open-source Java HTTP server.
After the development team had tried to argue that the application would never see as much traffic as two hits per second, and I had explained that a hit was not the same thing as a complete business process, just a request for a file on the webserver like all the images that were requested when the front page was loaded; they finally dedicated some time to fixing the problem.
The problem was fixed by changing the heap size parameters for the JVM. The development team didn’t understand why changing the settings made the problem go away, but they were just happy the problem was no longer occurring…this not really the sort of thing that inspires confidence in the abilities of a vendor’s development team.
What you have experienced is probably 1 in a 100 possibility….where the developers dont know what they are doing…
Consider a Web portal that hosts about 100 applications out of which may be 10 to 20 are used the most and the rest are either petty apps or static pages. Your experience would drive a load test with all the 100 apps (a whole 6 month project just for performance testing)
If it happend at 2 hits/sec, we dont need a tool like LR (which is very expensive too) to prove that…
The real value of performance testing and tools is when used for high volumes where manual testing is not at all feasible….
If i had all the time in the world, I would go about testing every functionality – otherwise stick to the famous “heavy hitters, critical BPs, resource intensive” functionalities.
Typically when deciding what test cases we need to test, “resource intensive” decision should come from the infra and dev teams.
What was the original heap size for the JVM?
What was the original garbage collection frequency under load?
Once I observed a similar behaviour and it was caused by a frequent garbage collection (almost all CPU cycles were spent on GC).
I have begun to categorize load testing into 2 different types because of similar scenarios I’ve seen at customers. First type is your typical high-volume “load testing” which everyone knows, the other is “diagnostics testing”, which is the type of lower volume testing you describe here. Both are beneficial, while diagnostic testing fits in with the mantra of test early and test often. This neatly into the way that many development organizations are moving already, using Agile, Test-driven and other iterative processes. If you already made the leap into tools that perform detailed analysis (i.e. LoadRunner), there’s no reason to relegate them to the end of the testing cycle if they can be used to proactively discover issues earlier in the development process.
Since traditional performance testing is done at the very end of a release, you might not find major scalability issues until this stage, when in fact scalability problems might be revealed in the application code, even at low volumes. The advantage to what you’ve described is that testing can become an iterative process where feedback is given more regularly to the development team and the scripts for load testing can be developed much earlier in the development process in these “diagnostics” tests.
While I agree that you don’t want to try to test before the functionality has had time to evolve a bit, if you have already invested in LoadRunner, then you’re able to utilize the tool more consistently throughout the dev process rather than waiting until the end, when scalability problems are much more difficult and expensive to fix. One other advantage to this approach is that with LoadRunner’s Java/.Net Diagnostics module, you can provide feedback to development on issues occuring at the class/method level. There is also a free version of the Mercury profiler that uses the same technology as LoadRunner’s (albeit doesn’t handle more than single user traffic), which developers can use on thier dev boxes: http://download.mercury.com/cgi-bin/portal/download/searchResult.jsp?type=2
-quote-
The development team didn’t understand why changing the settings made the problem go away, but they were just happy the problem was no longer occurring…
-endquote-
O.o (Tilt) they did not understand?????