When running a training or mentoring session, people often ask what runtime settings they should use; as if there is a magical list of settings that will always be correct for any testing situation. Obviously you select runtime settings that are appropriate for what you are trying to achieve with your test, but the funny thing is that there are actually a small list of settings that are usually appropriate for most situations. Read on…
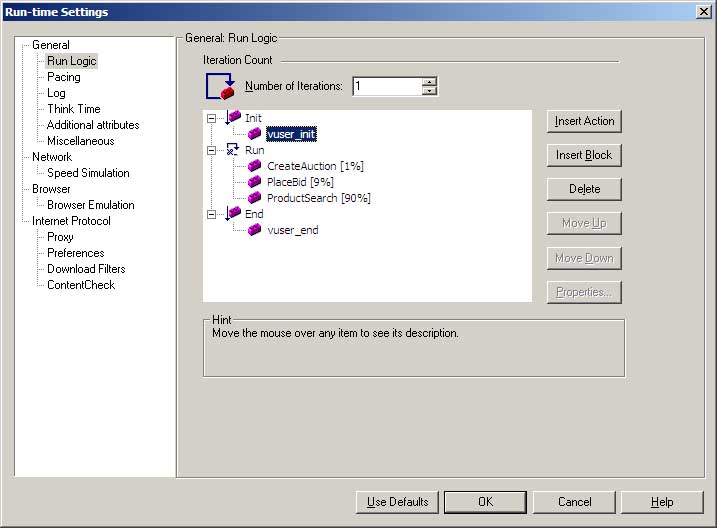
Whenever I am using a vuser type that allows multiple actions in a single script, I will create a separate action for each business process and put appropriate percentage weightings on each action. It is very unusual to have to do anything more complicated than this. I don’t usually use the “sequential” option or create blocks unless I need to have fractional percentage weightings for a business process – percentages must be integer values, so to run a business process 0.1% of the time you could create a block that runs 1% of the time, and put an action in the block that runs 10% of the time.
It’s also rare to set a script in a scenario to run for a specified number of iterations (mostly done by time or set to run indefinitely). Generally “number of iterations” is only used when running the script in VuGen.
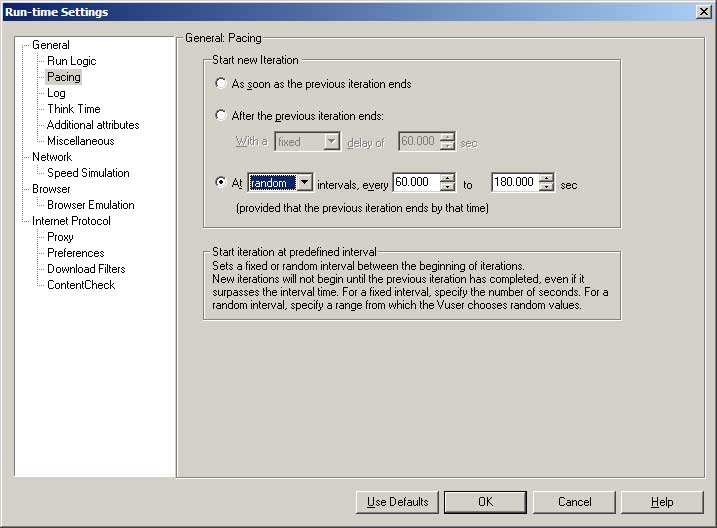
- “As soon as the previous iteration ends” is used when running in VuGen or when loading/verifying data. Do not use this for load testing
- I have never seen the point of the “After the previous iteration ends” option. Why would you want to run an unknown number of transactions per hour against the system?
- Don’t use the “At fixed intervals”. If something causes your users to become “in step”, they will tend to stay that way and continue to all hit the server at the same time.
- “At random intervals” is definitely the way to go. Obviously for your users to create a certain number of orders per hour the iteration time must average to 3600/num iterations in an hour. Do not make the lower boundary value any bigger than the maximum time it takes to complete the business process, or you will end up creating less transactions per hour than you intend to.
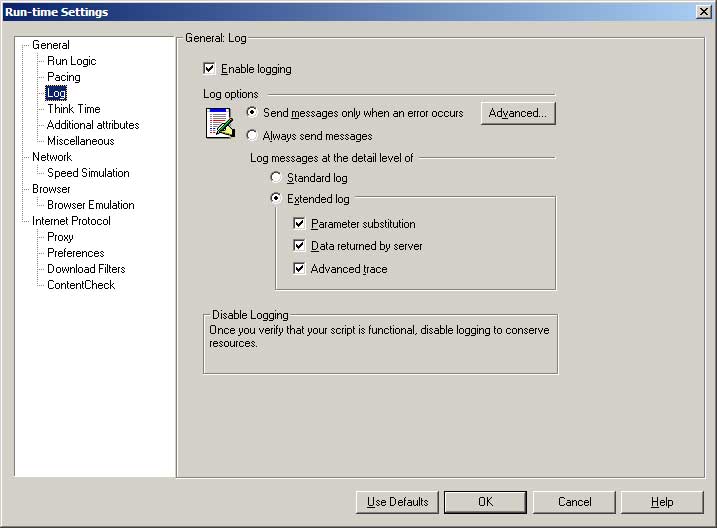
- Logging creates additional overhead on your load generators, and can create huge log files.
- I log absolutely everything when debugging in VuGen.
- When running the script as part of a scenario, I leave extended logging on but change the logging to “Send messages only when an error occurs”. This gives a little more information than turning logging off entirely, and won’t create any additional overhead while everything is running smoothly (and if the system is not running smoothly you are going to need to stop the test and investigate anyway).
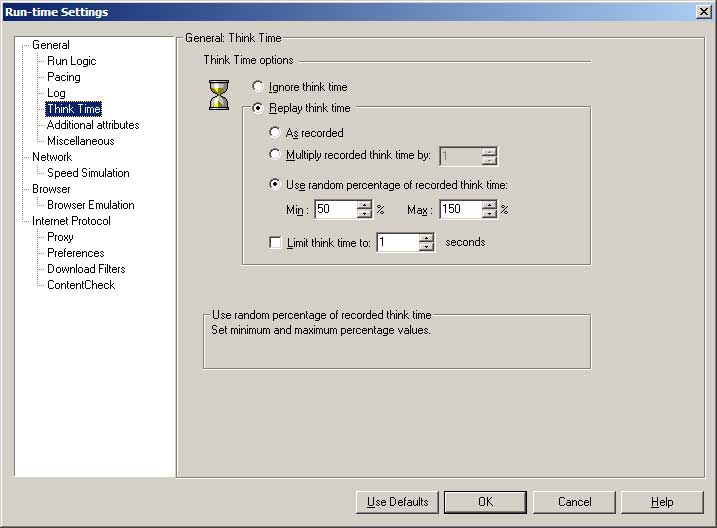
- Just like the pacing setting, I think that it is a good idea to put some randomness in your think times.
- I use a random percentage of 50-150% of recorded think times.
- Use “Ignore think time” if you are debugging in VuGen or if you are loading/verifying data.
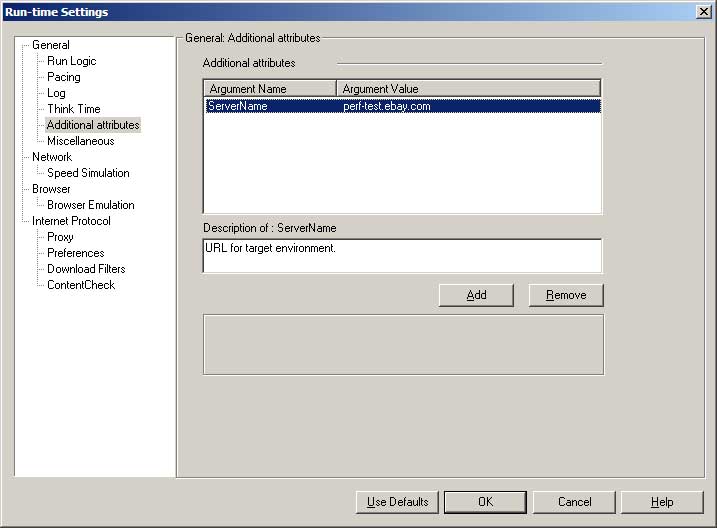
- This option is ignored by most people. It is used to create a parameter with a given value without having to edit the script (as runtime settings can be overridden in the Controller).
- In the screenshot I have created a parameter of ServerName with the address of the test environment. If you were testing in more than one test environment at a time, this would make save some time.
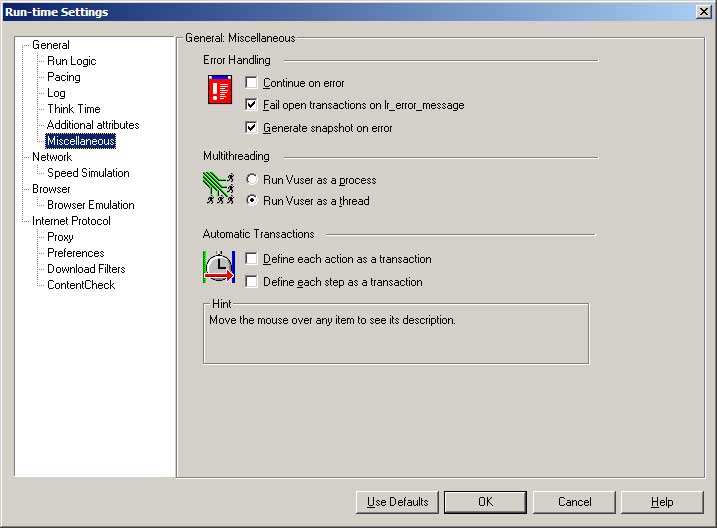
- Continue on error is generally only going to be used if you have written code to do something when you encounter an error. Usually the default behaviour of ending the current iteration and then starting the next one is sufficient). I don’t advise anyone to try to write a script that handles errors in the same way as a real user because it will create a lot of additional work for very little benefit, but doing something simple like writing some useful information to the logs and then calling lr_exit(LR_EXIT_ACTION_AND_CONTINUE , LR_FAIL) can be useful.
- “Fail open transactions on lr_error_message” should always be ticked. If you are raising an error, you should fail the transaction step that you are performing.
- “Generate snapshot on error” is useful. If it is a web script, any error messages should be added to your content check rules.
- Run your virtual user as a thread unless you have code that is not threadsafe or there is some other reason to run your virtual users as a process. The overall memory footprint on your load generators will be higher if you run as a process.
- I never use the “Define each action as a transaction” option. If I want a transaction in my script I will add it myself with lr_start_transaction.
- I never use “Define each step as a transaction” either. If it is a web script, I can use the transaction breakdown graph to get this information, otherwise I will add the transactions myself.
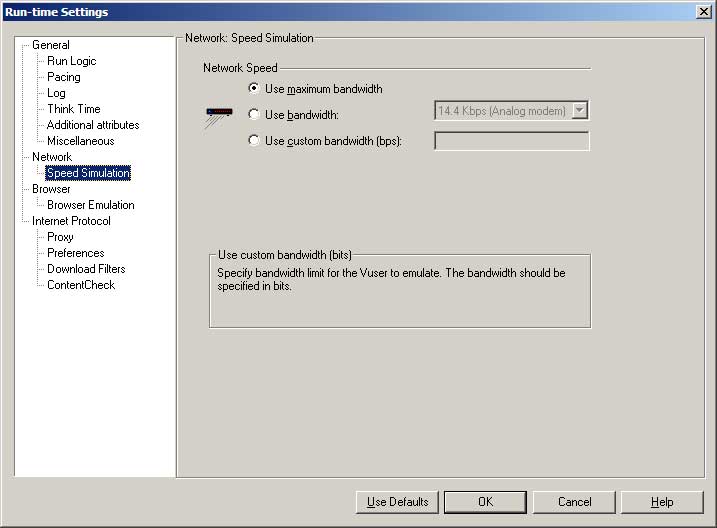
- Not all vuser types have this option available.
- Most of the time my virtual users will use the maximum bandwidth.
- If I want to emulate users with bandwidth constraints, I will do this in a separate scenario.
- Google calculator is handy to calculate bitrates if your bitrate is not available from the drop-down list e.g./ “256 Kbps in bps”
All of the following settings only apply to web-based scripts. Each vuser type will have its own runtime setting options. It is important to know what they mean and how they will influence your test results before running any tests that you plan to report on.
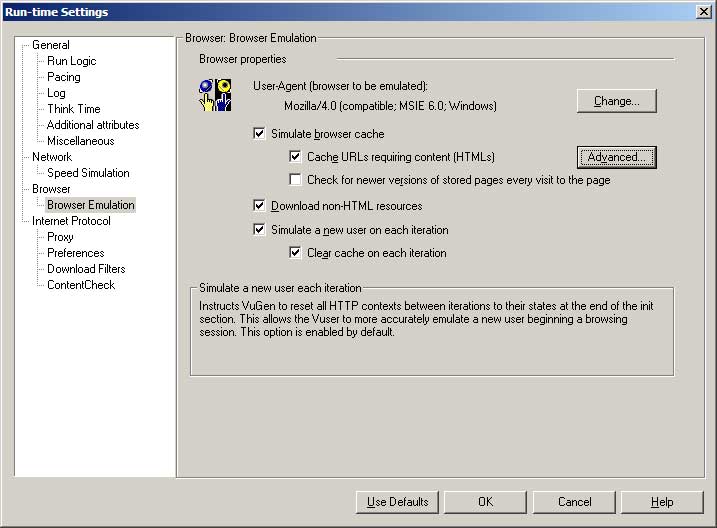
- Some people get confused by the User-Agent (browser to be emulated) setting. If 90% of your users use Internet Explorer 6.0 and the rest use Firefox 1.5, you don’t have to change the runtime settings for your users to match this. All it changes is the string that is sent in the “User-Agent” field of your HTTP requests. This is completely pointless unless your application has been written to serve different content to different browsers based on the User-Agent field.
- TODO
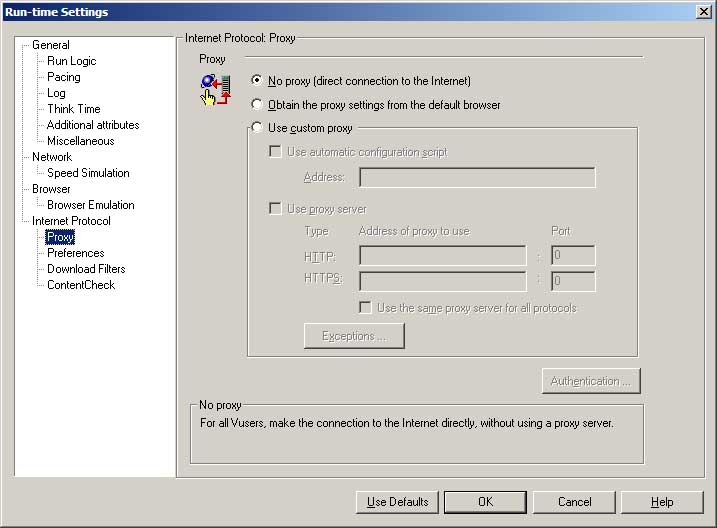
- Generally people won’t be using your web applications through your proxy server, so it shouldn’t be part of your test either.
- If you start getting errors that are due a proxy server rather than the system under test, it will just confuse the people who have to fix the problem.
- A proxy server will also make IP-based load balancing ineffective.
- If it’s an intranet application and everyone will be using the application through the company’s proxy, then the proxy server should be explicitly declared to be in scope for your load test. You should make sure that you have an identical proxy server for your test environment, or that you have permission to be generating load on a piece of Production infrastructure.
- TODO
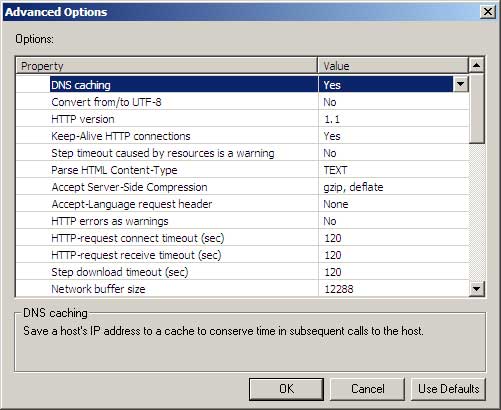
- These settings are default values specified by Mercury, rather than being inherited from the web browser that is installed on your workstation. Generally you will not need to change them, but be aware that they are here.
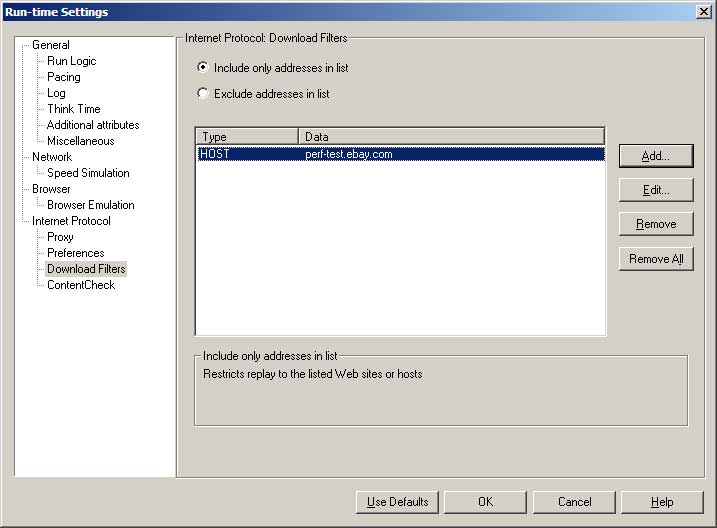
- Download filters are a quick way of preventing your scripts from downloading content from certain URLs or hosts/domains.
- I generally use this feature when the web application in the test environment contains third-party images used for tracking website usage (e.g. images from Webtrends or Red Sheriff etc).
- I think it is better to specify which hosts your script is allowed connect to, rather than which hosts your script can’t connect to (because it’s easy to miss one accidentally, or the application may change and refer to a new third-party domain).
- Use web_add_auto_filter if you want to specify this in your script rather than your runtime settings.
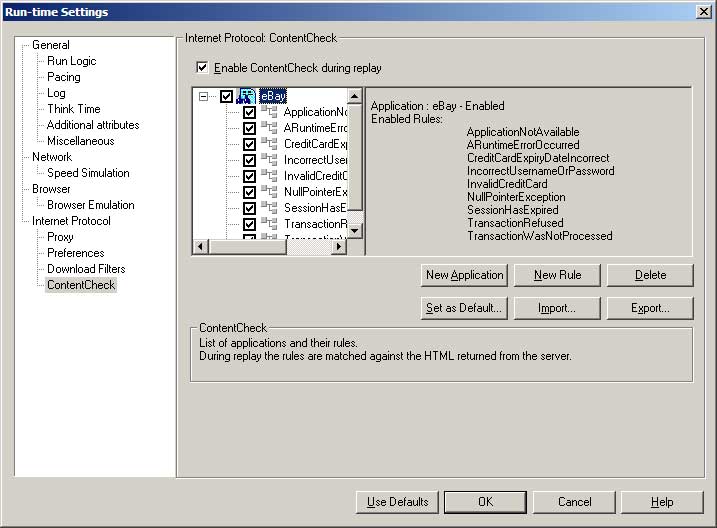
- I have talked about Content Check rules before; I think that if you aren’t using them already, then you are not getting the most out of the LoadRunner feature-set.
Related Posts



98 Comments
Comments are closed.
Hi,
This update was useful as it helped me understand certain run-time features which I wasnt using so far. Thanks!
I have one doubt regarding one run-time setting that you have mentioned. Under the Logs – > Extended Logs, you have selected all the three options, dont you think for a test with longer duration (running into hours) and for large number of users this could be an issue as this would in-turn generate lot of data which might not be actually required?
Thanks,
KK
Thanks for the comment Kunal, I have updated the text under the screenshot to explain my recommendation (it only logs when there is an error – you shouldn’t be getting a large number of errors).
Cheers,
Stuart.
Fantastic post! I was aware of most of this, but I still managed to pull a few gems from here. Thanks!
Chris
http://amateureconblog.blogspot.com/
“Whenever I am using a vuser type that allows multiple actions in a single script, I will create a separate action for each business process and put appropriate percentage weightings on each action.”
I have been advocating this for years. As we consult for new clients, and help them improve their performance testing processes, this is one of the items that I advocate under performance testing. I usually find they create one script for each click-path or BP, and these dozens of scripts at the same time, or worse, one at a time. Using a single script with action-weighting helps force the tester to get a thorough load on his system, simplifies increasing user load (you only need to increase VUsers on one script, not 30), and simplifies test management.
I think this item is worth post all on its own.
Overall, excellent post. This needs to be a Top Page.
Nice work.
Hi,
Is there any way to record Window download box in Loadrunner 8.1?
I tried many things butno luck,it seems that its not recording that download dialog box.
When I click on “export” tab, download dialog comes with 3 option:
1. Open
2. Save
3. Cancel
I’m choosing Save but nothing getting recorded in Loadrunner.
Please help.
Hi Deepanshu ,
For download the file it will work by load runner.
You do onething first check manually the size of the file.
Check manually in output log in that transaction the file size.
!00% its working by load runner.
If you want to see the size of the file through load runner then you use the function Web_get_init_property.
About youe query that is save,open ,cancel that is Client side Activity.
Thanks
Arun Prasad Mohanty.
Camcorder is a better tool to record a dialog box in LoadRunner.
Its really useful, especially the Content check rule is a good idea to implement.
Great post, but I have an unrelated question. When purchasing a load testing software package, how do you decide what number of vusers you should get a license for? Is there some rule of thumb I should use to calculate this number? Our highest volume app is a student portal, with a max of 10000 successful user logins with in an hour. Our total student population is 50-60K. Based on these numbers can you determine a good number of vusers we should purchase. I know that 500 vusers can translate to more than 500 “real users”. Any help would be greatly appreciated.
Hi,
Have few questions regarding Network Buffor Size.
1. What constitutes a Network Buffer Size?
2. Is it a buffer on NIC card or RAM?
3. What dictates the Network Buffer Size?
4. For a best practise, how will we know what the size should be, before test execution?
Any help would be greatly appreciated.
Regards,
Prashanth
Great reference for people that requires a knowledge of Runtime Settings! 🙂
My website to complement:
http://loadrunnertnt.blogspot.com
Regards
Hs
Is there any way to record Window download box in Loadrunner 8.1?
LoadRunner (Web HTTP protocol) records the HTTP traffic between the client and server. It does not record GUI actions. The download box is a GUI feature of IE and selecting the save or open options have no impact on the client-server communication. This means that you cannot record the download box and it has no impact on a recorded load test script.
Ben Simo
http://QualityFrog.com
hi,
I want known that which Language is use for LoadRunner.And How knownlage required for that Language.
Anish
Hi Anish,
In load runner Scripting we are using ANSCI C.
You need to know knowledge about c programming.
Thanks
Arun Prasad Mohanty.
Ansi C
Hello,
I am trying to simulate a realtime scenario where I need to open multiple browsers using different users in the same script.
Is it possible using loadrunner?
thanks
Avis
Hi,
Did you find a solution to this? Please share……….
Noopur.
Hi Avis,
In standalone mode only we can choose the browser what ever we want to reocrd the script. but if you are running the scenario in controller/performance center it will automatically invoke the default browser to simulate the load on server
Thanks,
Varaprasad
Hi!
IE7+loadrunner 8.1
failed to create snapshot, why? what could be the reason? is there any settings available to activate?
sugu
I want to know about the parameterisation of the load runner script.in detail
Parameterization in load runner
Hi, can u tell me how to run QTP sripts from Loadrunner, and for doing this what r the things one need to takecare.
Hi, can u tell me how to run QTP sripts from Loadrunner, and for doing this what r the things one need to takecare.
Hi
1. How to run QTP scripts from Loadrunner, and what are the settings to be changed in LR
2.When QTP script is called into Loadrunner, how to Correlate it…?
2 satish:
You can read the following article to find out how to run QTP scripts from LoadRunner:
http://motevich.blogspot.com/2007/11/execute-qtp-script-from-loadrunner.html
Hi,good post!
May I ask a question?
I want to know how loadrunner calculate the data to generate the graphs.
Thanks!
When are you going to fill in all the TODOs 🙂 I am missing some intriguing information in the RTS>>Browser Emulation>>Simulate Browser Cache>>Advanced.
Hi, you all here seems to be very good in Load Runner. I am new to this subject and also new to QA… I am now learning Mercury Load Runner 8.1
I have started the tutorial that comes with the application using MercuryWebTours web site. One thing is not working may be you can help me… i tried to use parameterization so as when my test run it will pick the values in the data grid which contains three values (e.g. Aisle, Window and None) However in my log i cant even see the word Parameter to check whether it is working or not.
I am getting the warning.
Action.c(120): Warning -26548: HTML parsing not performed for Content-Type “*/*” (“ParseHtmlContentType” Run-Time Setting is “TEXT”). URL=”http://127.0.0.1:1080/mercuryWebTours/FormDateUpdate.class” [MsgId: MWAR-26548]
Action.c(120): web_url(“FormDateUpdate.class”) highest severity level was “warning”, 3058 body bytes, 159 header bytes [MsgId: MMSG-26388]
Action.c(128): Warning -26548: HTML parsing not performed for Content-Type “*/*” (“ParseHtmlContentType” Run-Time Setting is “TEXT”). URL=”http://127.0.0.1:1080/mercuryWebTours/CalSelect.class” [MsgId: MWAR-26548]
Action.c(128): web_url(“CalSelect.class”) highest severity level was “warning”, 227 body bytes, 158 header bytes [MsgId: MMSG-26388]
Action.c(137): Warning -26548: HTML parsing not performed for Content-Type “*/*” (“ParseHtmlContentType” Run-Time Setting is “TEXT”). URL=”http://127.0.0.1:1080/mercuryWebTours/Calendar.class” [MsgId: MWAR-26548]
Action.c(137): web_url(“Calendar.class”) highest severity level was “warning”, 3018 body bytes, 159 header bytes [MsgId: MMSG-26388]
If anyone can help me please.
Thanks for your response.
Mr. Sanjeevee Paniken
Hi Sanjeevee Paniken,
If you want to see the parameters as you have done in the script then do one thing go to the runtime settings-log-extended log-then check the radio button prameter substitution.
Thanks
Arun Prasad mohanty
Hi.. could any one of u please provide for the follwing error:
Starting iteration 1.
Starting action Action.
Action.c(4): web_add_cookie was successful [MsgId: MMSG-26392]
Action.c(5): Error -26624: HTTP Status-Code=407 (Proxy Authentication Required) for “http://www.google.com/” [MsgId: MERR-26624]
Action.c(5): Warning -26200: At least one of the resources specified by EXTRARES has not been downloaded due to the above error(s) [MsgId: MWAR-26200]
Action.c(5): web_url(“www.google.com”) highest severity level was “ERROR”, 2662 body bytes, 778 header bytes [MsgId: MMSG-26388]
Ending action Action.
Ending iteration 1.
Same issue can anyone tell me to reslove this
Hi,
I am using LR 9.0 first time and I have few doubts.
Can anyonep lease clarify my doubts.
1. I need to browse some static content and then select some dynamic item from web page and from there i need to download pdf. I have to calucate time to perform this action.
I have recorder and its giving problem at the time of replay.
saying that
“Microsoft Visual C++ Debug Library
Debug Error
Program path:
Abnormal program termination
Press retry to debug the application”
When i click on retry the test windom automatically closing.
Hi,
I am new to loadrunner. But I am facing a wierd problem while recording. So I would appreciate any help regarding this.
I have downloaded the LoadRunner 9.1 Evaluation version from the HP site. I am trying to record opening a report (in a new window) in a Reporting platform. But looks like only the frame of the report is getting recorded but not the tabular content in the report.
These are the step I followed:
1. In VUGen, I openned a new script and chose Web(HTTP/HTML)
2. Then just started to recording as an ‘Action’
3. I stopped recording when the report came up with all the data, in the new window
4. When I replay it on the report frame come up but not the data.
Is there any initialization or any extra setup I can do to solve this.
Appreciate your help.
Thanks,
Ananya
Hi Stuart,
thats a good reference for ppl looking for RTS. I came across lot of Co’s asking me to explain these settings and now I know where I have to redirect them.
When are you planning to fill the “toDO” part? I am much interested on your notes for “browser emulation”settings.
Cheers,
AJ
Hi
This is Suman.How to calculate the think time for 300 user and 1 hr testing wid ramp up of 5 users for every every minute
TPS = Users/Think time + Response Time
So you will have to get info regarding Expected TPS( transaction per second), Expected response time. You have user load=300.
Hi Suman,
Run the scirpt in standalone mode and calculate the total time taken for 1 user and according to that calculate for 300 users that depend on total number of vusers assigned to that particular script
The sceenshot is not created in loadrunner for “web click and script” protocol does any has a workround.
-Thanks in advance, Joe
Cool Stuff…. I may have missed to read this part. But regarding the Content Check. Once I have it enabled, then how can I control the script or to put a trap when an error occured and have the script to go to the next iteration?
Thanks,
Manny
Hi ,
Very nice article!!!!
Thanks For sharing it!!!
You don’t think if we don’t enabled extended log -> Data Returned by server, we are not in position to check why some users were failing at a particular page.
Sometime it happens that error comes when load is there on application.
But when you check manually then application works properly.
Can any one explain “What is the difference between HTML based script recording and URL based script recording”? . It could be better if anyone explains the RECORD setting in LR.
need to automate the connection using loadrunner 9.0
oracle oms 6.3.1 is used .
java 1.5 and oracle 10g for backend .
is there any issues in connecting aswell http/html wich is better to use?
Anish, Loadrunner is developed in C language
Good article, i really like it. I am doing a bit research about LoadRunner and i found also macrotesting http://www.macrotesting.com to be very good source. Thanks for you article
Regards,
Prem
Hi All,
Sorry for my ignorance but I’m having a hard time with Loadrunner 9.5 to test a website. I just need to get results in the form of throughput when running 1000 simultaneous users but I’m not sure if I’m doing it correctly.
Please advise ASAP.
Regards,
Gurpreet Singh
Hi All,
I’m recording a script and then running a scenario but not getting required results.
Please help ASAP.
Regards,
Gurpreet Singh
Hi All,
I need to get actual steps to execute performance & load tests for our website using LR 9.5 and show some meaningful results to my boss.
Please reply ASAP
Regards,
Gurpreet Singh
Hi All,
I am facing a problem while generating the Vuser script in Loadrunner8.1. That is I am recrding in web application in that there will be an alart box ,So while recording it is not identifying the action i have taken on that alart box. Please help me in this regard. How to record the action on alart box???
How can we use the argument specified to use a different environment/URL during the run? I have defined it in the argument tab of Run Time settings, but when I replay the script, it runs in the same environment where I recorded the script.
Can you pls confirm?
Thanks
Excellent information. It would be nice if you can fill the <<TODO sections also. Regarding the section
“It’s also rare to set a script in a scenario to run for a specified number of iterations (mostly done by time or set to run indefinitely). Generally “number of iterations” is only used when running the script in VuGen.”
I think the number of iterations are useful when we run with the option “run until completion” in controller.
Hi,
My name is satish I am new to the software testing.
I am learing Load runner in my self I have one doubt
I record one sample google site it is sucessfully recorded while repalying that script it is giving Error code 26610 and it is dsipaying Http-Status Code =502(proxy error(The ISA server denies specified URL))for “http://www.google.co.in/”
I am using load runner 9.0 My run-time settings below
1.Using custom proxy
2.Check the proxyserver check box
3.provide the IP and port nummber
4.Click on ok
5.click on the replay link at the time loaderrunner proving Error -26610:
HTTP Status-Code=502 (Proxy Error ( The ISA Server denies the specified Uniform Resource Locator (URL). )) for “http://www.google.co.in/” [MsgId: MERR-26610]
Could you any please hepl me on this and how to set the porxy server settings.
“I have never seen the point of the “After the previous iteration ends” option. Why would you want to run an unknown number of transactions per hour against the system? ”
There is actually a very good reason for this option if you’re doing stress testing – by which I mean testing where you increase the load the system is under and observe how response times increase. With this setting you can in theory achieve a stable rate of throughput even though part of the system is 100% utilised – the longer input rate of transactions reaches an equilibrium, even though you can’t predict what that rate will be.
If you don’t use this setting, you’re just thrashing the system as hard as it will go, and this will tell you nothing about the behaviour under stress. Think of it simulating a real user – just because a page takes longer to get served to the user wouldn’t normally mean they would respond to it quicker.
Mark
Am working on lR and am assigned a task to script a java based website,. which uses applets,. now i need someone who can help me to write logic,.
to fill the data in all the cells displayed,. and then save it,.
Appreciate if anyone could ping me to discuss further,.
I can share my desktop so that u can look into the application to be tested and let me know ur views,.
Niha.
What is the significance of ordinal value in correlation function?
can i get the testcase or test script of load runner?
Hello.
Avery helpfull post indeed!
Just be aware of changes applied to Scenario you are running.
This is: When you already have an existent scenario created and /or “saved” ypu cannot used again if you modify the scripts over Run Time Settings.. in a strange way.. Scenario gets married with an specific version of your script (the one wich it was created with) and even if you perform canges over any of the scripts for tat scenaio WILL NOT BE APPLIED.. I just found this out. So if anyone is having problems with that should try to use a NEW scenario or well not just apply changes over existent script and save it as NEW script “Save as”.
Hope this helps
Isaí Villarreal
what is the differance cpuload and utlization
i installed load runner 9.1 but i am unable to run even the sample application.do i need to change any settings?can i use this for real time scenarios?
u cant use ..u need liscened version..jst uninstall load runner
Hi,
I am beginner and found this pot very useful which really inspires me to learn and explore more.
I have a question for you at this moment.
I have a script, login action, iteration part Action, and logoff…means I need login then iterate the main part of the script and then logout.
When I try to iterate the part of the action, it does not take a different value, but is taking the same value each time. Please help me with a solution.
I tried puttin a block…it didn’t work
I tried puttin a for loop it didn’t work
Pls help. 🙁
thanks Stuart for bringing this wonderful Informative knowledge enhancing site.
There is just one suggestion from my side – there are lot of learners who are using this Tool and are facing lot of doubts. Can you please start some issue resolving/guidance post where users can ask and clear their doubts and get resolve their flow execution related issues? It would be a great help from your side.
Thanks once again.
Currently iam facing below error when iam Replaying the recorded Script (it contains Login-> click on Flights tab – > Log Off scenarios)
Error Msg:
Action.c(59): Error -27987: Requested image not found [MsgId: MERR-27987]
Action.c(59): web_image(“Search Flights Button”) highest severity level was “ERROR”, 0 body bytes, 0 header bytes [MsgId: MMSG-26388]
I dont know why Image error is coming, i tried hell lot of things from different tutorials but got no success. Stuart can you please help me with your expertise?
Every person who asks a stupid question completely unconnected to the subject of the original post on (a six year old!) blog goes on my ‘do not employ’ list…
Hi
I would like to simulate SilkPerformer – Queuing Workload in LoadRunner;
– I am using 3rd option in Pacing section on Script A and dividing total time of other script (say, Script B) with Number of iterations of Script A
Do I need to do something else also or this is fine?
Regards
Anubhav
Hello All,
I have created an iOS app from which you can set/calculate all you performance testing scenarios on your iPhone/iPad/iPod touch.
Hope it helps the performance testing community.
App Store Link:
https://itunes.apple.com/us/app/pacing-calculator/id656498467?mt=8
Support Site/Tutorial Link:
http://krangiosdev.wix.com/pacing
If you need help shoot me an email at my support site.
Cheers,
Kiran
Hi,
I am seeing the following error when running a webservice script from the controller i.e. “Auto Log cache is too small to contain the message” and the script is failing with memory violation error. Can somebody help me on this.
To bump up the cache size, use the Replay run time settings for logging, advanced, and set the “size in KB of the log cache”.
Sorry, can’t help you on memory violation errors 😉
can any explain about difference between controller runtime settings and vugen runtime settings?
I mean if i provide runtime settings in LR script then do i nedd to provide runtimesettings in controller also?
Hi,
Please tell me, how to give this percentage to actions. I tried to give percentage in proties of block but I am not able to give percent.
Hi Stuart
Regards from Mexico! I have a doubt, about is possible in CITRIX Protocol evaluate the response from emergent screen and continue with other actions and return to the original script code, I tryed this based on if is succesful the transaction and write in a file errors, but the request is. If error take actions and restart with the next iteration and test record.
Saludos!
Hi Stuart,
In our case, we deal with a WPF Client based on .Net 4.5 and WCF Asynchronous Web Service calls for every Business Flow(typically a Transaction like Login, Save, Open..etc) Each of these Actions have, on an average, say 10 asynchronous web service calls.
Ideally since the calls are asynchronous, we have should be considering the call that takes the max response time as the time for the entire action to be completed. Right?
Now here comes a tricky situation, if some the calls become synchronous then how can we track them and their response times?
So far we have been tracking all of this behaviour via Fiddler’s Timeline feature for every single flow.
Is there any better way of doing it from LoadRunner
like Web_Concurrent_Start()..but I came to know about a limitation that we cannot capture individual webservice calls using the above function.
Please suggest how to effectively capture response times of asynchronous webservice calls
We are using LR 11.52
Hi Everyone,
can you please tell me how to make Loadrunner wait in Web protocol until an image is disappearing?
Hi,
I am to HP LoadRunner. Just now i started HP LR. I am facing a problem. I had created a Login / Logout script for website in HP Vugenerator. after this when i am running this script in HP LoadRunner Controller then it taking very much time to complete as compare to Vugerator.
HP Vugerator taking: 1 Minute 20 sec.(Single User)
HP LoadRunner Controller taking: 5+ Min (Single User)
Could you guys help me what and where i am doing wrong.
Regards,
Sanjay Bansal
system.platformNotSupportedExecution:Operation is not supported on this platform
on OS- windows-XP
latest version of load runner
i m getting this errros while generating users, so any extra patch should i need?
Thanks..
Hi,
I am new to LR. I just wanted to confirm if we could execute Vugen 11.50 scripts through Controller 8.1?
Heena.
Hi
I am beginner of LR, have a query (mentioned below), please help me with the solution.
lemme take the sample example given with Load Runner (web tours – flight booking tool)
After selecting the place, dates, seat type and seat arrival depends on the input the list of flights will be loaded in next page with radio buttons. If i parameterise the places and dates the values will differ. so how can i correlate / parameterise the flight selection part?
please help
Is it possible to view runtime viewer/browser of particular user while running a load test.
Thanks,
Usman M
Hi Usman,
Yes it is possible.. While running the load test, select the number of vusers in running state. Click on the Vusers button. Now right click the specific Vuser which you wanted to view. And then select “Show Run Time Viewer”
Hi,
vugen: 11.04
Controller : 9.1
IE:8.0
Protocol : web click and script (GUI based script)
Application doveloped on javascript and Jquery
we recorded few scripts one appliaction (Javascript and Jquery based application) six months back those are working fine vugen and contorller
Benchmark:
Throughput: 5,696,380,731
Average hits/second: 107,111
Devlopment team changed now UI for application by using the new jquery JavaScript library (making heavy use of this new jquery version in new release). now for all scripts i modified the code for few transactions. now scripts are working fine.
but issue is Throughput, hits and passed transactions are much less and the transactions response times are much slower.
throughput: 3,075,974,896
Average hits per second :26.974
Note we manual checks during the last load test and the application was responding fast (around 1 sec response time). The load test shows at the same time response times of up to 49 seconds.
Additionally we did a load test with only one vuser and one transaction per scripts and measured the response times. These were then compared by manual measurement done by the dev team (see attached). Again LoadRunner was showing much higher response times which should not be the case.
could you please help on this issue.
Thanks in advace,
hi
I had a doubt where performance center logs are saved??
hiiii
when i start my server plz below show the message and please solve my problem fastly
starting the webtours apache server…
press CTRL-C or close the window to exit 🙂
httpd.exe: Could not reliably determine the server’s fully qualified domain name
, using 192.168.9.1 for ServerName”
Hi All, Am getting 500 internal server warning message is coming when application launch. Do u hve any solution?
If the HTTP 500 error occurs when you use the application manually (check your VuGen recording/code generation log), then it is a defect with the application under test.
If you are getting the HTTP 500 error when you run the script with a single user, then there is something wrong with your script (missed a value that needs to be correlated, bad data, etc.).
If the HTTP 500 error only occurs under load, then ask yourself if the load you are running is realistic (hopefully you did a Workload Modelling exercise). If it is realistic, then there is a load-related problem with your system under test. If your Peak Load workload model is not realistic (e.g. waaay too much load), then re-test with realistic load, and see if the problem is still present during your stress test.
This is not a problem that you should *fix* by changing your script’s runtime settings.
Hi Stuart,
Thanks for the reply.
Issue got fixed once after updating the slash (\) of my end point URL.
for ex: google.com\
What is the maximum load we can give through controller from a single machine that too on trial version.
LR Version: 12.02
Hi ,
I am getting below error while recording
“There is no Internet Access. You may be unable to record and execute the business process.This may affected you even actual business process does not require an Internet Connection. Since the selected browser my require Internet access. Continue”
What is the reason for this error?
Could you please let me know the solution.
Hi Stuart,
I am encountering with some error in LoadRunner Controller. However my script works fine with 50+ iterations. Please find below the error snippets as follows:-
2 -79992 Action.c(7): Error: Failed to find SapGui component by ID “sbar” 7 Cntrl 7 1 1
2 -79984 Action.c(82): Error: Failed to get the “VerticalScrollbar” property of SapGuiComponent “TableControl” 1 Cntrl 1 1 1
2 -79946 Action.c(7): Error: Failed to get the status bar text 7 Cntrl 7 1 1
2 -79910 Action.c(7): Error: Failed to set OKCode “/niw31” 18 Cntrl 18 1 1
2 -79906 Action.c(109): Error: Failed to press button “Release (Ctrl+F1)” 16 Cntrl 16 1 1
2 -79638 Action.c(82): Error: Table – Failed to fill with data from Table parameter “{data}” 10 Cntrl 10 1 1
As per as I am concerned with above errors, specific component is not loading at that moment when controller execute the script with multiple VUsers. I am doing load testing of SAPGui app. Response time is intermittently high.
I tried to increase/decrease lr_think_time but it didn’t help out. Could you please help me to eliminate those errors?
Please find below product version as follows:-
LoadRunner: 11.50.0.0
VUGen: 11.50.0.0
Controller: 11.50.0.0
Analyser: 11.50.0.0
Please let me know if you need any other info, you can mail me @pravin.chauhan22@gmail.com.
Regards,
Praveen
Hi Stuart,
I had a question regarding the “Bandwidth Simulation” but don’t seem to get answers anywhere.
If I have a test with two injectors each running 50 users each (total 100 users) and if the bandwidth is set to 512 Kbps, what is the treatment? Does every user get 512 Kbps raising the total possible bandwidth to 512*100 or is shared by all the users i.e. 512/100.
Any pointers will really help.
Thanks.
Hi, Normally we performing the script in HP ALM and results also generated to open in HP Analysis tool. But there am having few questions:
1.Passed transactions are equal for the entire time we setup in scheduler(inclusive rampup/steady state/rampdown)
2.Total duration of the test performed 1hour. Is that need to focus only steady state where all the users are concurrently hitting to server. Bcoz, If we can calclulate one hour this much transactions were passed and then will expect this time will be these many transactions going to achieve. Is that the SLA deriving?
Hi Stuart,
I am getting error Web image step creation failed after replaying my recorded scriptt, Did I miss any option while recording ??…What is the reason for Web image step not creation..Please help me on this.
Thanks in Advance,
Naresh
Once we do replay- its getting script failed as error 27987 requested image not found
Hi this is Anusha. I am a test engineer with 3+ yr of experience in QTP ans Selenium & I need help regarding Performance Testing using LoadRunner (Real time load Scenarios & Vugen scripts).I wanted to know if you guys provide online training sessions for a certain pay. If there is such facility please let me know or if you have any friends who are proficient in LoadRunner and willing to help online contact me on 9059175858 or please write to anusha.gode1@gmail.com. I will pay the required amount for the course.
Hi i installed latest version of loadrunner. Am able to record the scrip, but after recording the script am not able to perform anything like editing code, exit from Vugen e.t.c, So plz provide the solution for my problem its very urgent..
when we have to go to url mode
HI,
We are getting problem for downloading document Through agent machine
how to solve this issue please give solution
Hi,
without using fopen function how to do download scenario in load runner please give solution.