![]() First off, the good news: if you are load testing based on a defined Workload Model, you are already waaaay ahead of a lot of performance testers. I am frequently horrified by testers whose approach is…well, just not very scientific. When their test case is “we’ll just throw some load at it and see what happens” or their load test has been defined in a way that is vague and imprecise, like “our test is to run load with x concurrent users”, then the probability of them not knowing what they are doing approaches 100%, and it is clear that their concept of performance testing is closer to a ritual than to a science.
First off, the good news: if you are load testing based on a defined Workload Model, you are already waaaay ahead of a lot of performance testers. I am frequently horrified by testers whose approach is…well, just not very scientific. When their test case is “we’ll just throw some load at it and see what happens” or their load test has been defined in a way that is vague and imprecise, like “our test is to run load with x concurrent users”, then the probability of them not knowing what they are doing approaches 100%, and it is clear that their concept of performance testing is closer to a ritual than to a science.
For those of us who want to run better, more realistic load tests, there are a few things to watch out for to make our Workload Model as accurate as possible. Read on for my tips…
Five reasons your Workload Model may be wrong
1. You have no data to build a model with, just opinions.
A company I worked at was launching a new website, and their launch was going to be on a popular morning show on national TV in New Zealand (population 4.6 million). Obviously they had no usage data to build a Workload Model from, so as a starting point, I looked up the ratings for the TV show, then made an (optimistic) assumption about how many viewers were likely to be interested enough to visit the website during the next ad break. It was like a performance tester’s equivalent of the Drake equation, where estimates are multiplied by estimates. Zero chance of being accurate, but hopefully a way to get somewhere near the right order-of-magnitude.
In other cases, for a new web application, someone else might have already made some guesstimates. Maybe there are some numbers that were used in the business case for building the new system, or maybe some usage predictions were made when estimating how many servers would be needed (for infrastructure costing).
2. A big part of your workload may not be from real users.
Bots visit every public website. Some, like GoogleBot, are generally well-behaved, but others don’t care if they cause load-related problems. For a gambling website I worked on, a huge proportion of their traffic was from scraping, as power-users and other websites compiled tables of odds for horse races, etc. I remember that their Ops team played a (fairly pointless) daily game of whack-a-mole as they blocked bad IP addresses on their firewall.
If you are building your Workload Model from Google Analytics, bot traffic will not be included in your usage stats. Google Analytics (and a lot of other analytics tools) rely on running JavaScript in the browser. Bots generally just make HTTP requests, and don’t render HTML or run client-side code (the exception being bots built on Headless Chrome).
If you are creating your Workload Model using data from Google Analytics, it would be a good idea to also check your web server logs. Note: this also picks up real users who are using privacy-enhancing browser extensions like Ghostery, NoScript, or Privacy Badger.
3. Users may not behave the way you expect them to.
I once worked on project for a large retail business that had a call centre so that customers could order over the phone. The application the call centre staff used had a screen that showed a roll-up of all the orders for a time period (default: one day). It was useful for staff to quickly find an order if the customer called back with an update. What I didn’t expect was for bored call centre users to be curious about more “management level” aspects of the business, like “how many orders have been placed this month?”, or “how many orders have been placed this year?” Running the report without filters would take more than 10 minutes and would grind the system to a crawl while it was running. The first I knew of it was when someone noticed odd periods of high CPU in Production, after Go Live.
4. The usage data you have doesn’t show the complete picture.
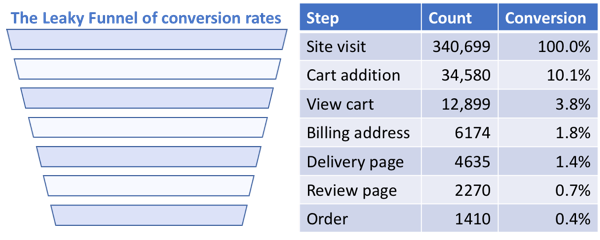
Many years ago, when I was preparing to load test a retail website, I requested details about order volumes, and a DBA sent a database extract with the number of orders per hour and the average number of line items per order. Unfortunately the order information stored in the database only told part of the story – the number of users completing their orders was dwarfed by the number of users who added products to their cart, viewed the total cost (including shipping) on the checkout page, then abandoned their cart…therefore not having any of their usage activity logged by the database. Talking to the Marketing team (who live and breathe conversion rates), I found that only 10% of shoppers who started the checkout process actually completed it, meaning that the Checkout volumes in my Workload Model needed to be 10x bigger than the order numbers the DBA had given me.
The Solution: Your Workload Model needs a feedback loop
I hope I haven’t discouraged anyone from building a Workload Model. Even if your model is not 100% correct, it is still an essential part of defining a load test that is clear and repeatable. Just as importantly, your initial Workload Model is a first step, which can be updated and improved as you learn more about how the application is used…which brings me to my fifth and final reason your Workload Model may be wrong…
5. Your website usage has changed, but you haven’t noticed (or updated your Workload Model).
Workload modelling is not something you should only do once; it is a regular exercise where you can update your model as new usage information becomes available. If your workload modelling doesn’t have a feedback loop, even a “perfect” model will drift way from reality. As a performance tester, you should be cross-checking your model against real usage data from Production at regular intervals (and you should always be checking the volumes that you tested with against the actual volumes observed after Go Live, so you know how accurate your testing was).
If you have your own ideas about pitfalls in workload modelling, please share them in the comments below.
Related Posts



One Comment
Comments are closed.
Oh, one more story from me. I was working on an internal web service which was called by a public-facing website. Each time an order was created, it would call my web service. I had initially assumed that my peak hour workload would match that of the public-facing website, and I could base my Workload Model on theirs. I was pretty surprised when I got access to web service logs from the past year. There were some huuuge spikes in web service requests per minute. Looking closer, these were from periods where there had been an outage, and the public-facing website was bulk sending all the orders it had been collecting while the web service was offline. I guess my point is that it is important to consider failure modes and “catch-up” scenarios when writing your test cases.