Mercury has just announced that they will no longer be re-selling the Shunra WAN Emulator. This means that I can let you in on a little secret – you can get most of the WAN emulation features for free by using a simple open-source program.
As performance testers, we know that an application operating over the network will perform poorly if there is not enough bandwidth available. We also know that response times for some applications are more affected by latency than others no matter how much bandwidth you have (eg/ an interactive multiplayer game like Quake is playable over a 56k modem, but completely useless over a satellite link that has 10 times the bandwidth). Sidenote: a good job interview question for a performance tester might be to explain the difference between latency and bandwidth, and its impact on application performance.
Load testing with bandwidth limitations is easy; LoadRunner gives you this feature for free. Latency is harder as it requires either a real WAN link, or something to introduce an artificial delay. An artificial delay can be introduced by a black box that you plug into your network (like those offered by Anue, East Coast DataCom, and Apposite Technologies) or by a piece of software like the Shunra WAN Emulator.
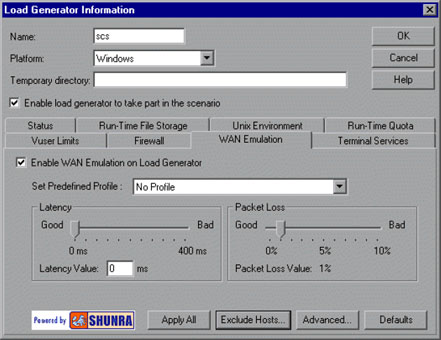
The free alternative to Shunra’s software is Dummynet, which was created by an Italian academic researcher.
Unfortunately Dummynet only runs under FreeBSD, but a tiny version of FreeBSD with Dummynet that fits on a bootable floppy disk is available for download. Personally, I haven’t seen a floppy disk for years and I don’t quite trust that FreeBSD (let alone a tiny version of FreeBSD) will support the variety of hardware it will encounter.
My preferred solution is to install FreeBSD as a guest operating system inside VMware. The hardware in the virtual machine is virtualised, so you don’t have to worry about driver support, and it is easy to distribute a VMware image between computers. The only other thing you will need to do is to set up a second network card in your computer and add it to the virtual machine.
The good thing about this solution is that it makes it easy to demonstrate latency and bandwidth-related performance problems manually, rather than expecting people to just accept your tool’s measurements. The only tricky part may be getting permission to plug your laptop into the network (or install the software) at a client site.
Related Posts



29 Comments
Comments are closed.
Two alternatives to the bootable floppy distribution are FreeBSD live CDs. Check out Frenzy LiveCD and FreeSBIE.
If you are testing a web-based application, you could use a proxy with a configurable delay (can anyone help me out with a link here?).
I just used Shunra in the latest L.R. 11.52. I did not like the older version of this product because it was very hard to configure and very limited. The latest LR 11.52 seems to be very well engineered and it seems they finally invested time and effort on this one. For example configuring is easy, it is per group not load generator so can can create many (don’t know how many) different locations in one load generator. The reason I used it was Mobile load and this seems to be the only tool that can provide a bottleneck per virtual user or in other words latency, bandwidth, utilization of bandwidth ect’ all per vu. hope this helps.
Hi Jack, I am also using Shunra for WAN Emulation in ALM 11.52, but it does not work properly. It throws many error. We have had support from HP team too. Still it is under working. How did you get it working? Kindly suggest me the settings and licences you have.
Thanks,
Manimozhi
this is cool.. gonna have to give it a try. i like the idea of a virtualized bandwidth emulator, thanks.
Shunra has commercially proofed tools from $499. See http://www.shunra.com
Bob; Do you work for Shunra ?
I have a similar setup where I work, on this setup I have registered a number of IP addresses for the virtual NIC and incoming/outcoming tcp/ip traffic has its own queue, this gives me the option to quickly switch between different bandwidth setups.
On top of this I have a Squid proxy so I quickly can try different setups without changing NIC configuration on my local computer, just to make it a tad easier.
My understanding is that for free you can limit bandwidth for individual user. You can’t, for example, simulate a bandwidth restriction for a branch (a group of users) that is a common case for corporate applications.
Bob (with an @shunra.com email address),
it’s great that a company like Shunra is keeping an eye on the technical blog community.
People should note that Shunra offers a free 5-day trial of VE Desktop. If you want to simulate the properties of your network on a Windows, Shunra is a good option.
Henrik,
excellent tips. Thanks for the comment!
Alexander,
You are correct that the “speed simulation” in the runtime settings is for individual users. I should have noted this in the post.
Great post! Another wonderful use for VMware.
This is nice, but if you have to use VMWare, then you have to buy VMWare, and then this solution is no longer free, is it?
Load testing with bandwidth limitations is easy; LoadRunner gives you this feature for free.
This is only true for individual vuser bandwidth limitations. LoadRunner limits the bandwidth per vuser. It has no option to limite the combined bandwidth of a group of vusers. Thus a reason in addition to delay emulation for needing some external WAN emulation.
Very cool idea. Do you know if there is a virtual appliance available for download with FreeBSD and Dummynet preinstalled?
Brent: VMWare offers some free products and a free alternative is Microsoft’s Virtual PC.
I have found alternative here:
http://www.xpidea.com/Products/tabid/53/ProductID/19/Default.aspx
Although, this product does not have all of the bells and whistles Shunra has, latency and bandwidth emulation is all I need. Good product!
M0n0wall will do latency and it is a free firewall.
http://m0n0.ch/wall/
Check it out 😉
It looks like Mercury/HP is re-selling the Shunra WAN emulator again.
They have some videos of the newest version here:
http://www.shunra.com/shunra-demo-center.php
And a press release here:
http://www.shunra.com/pr-09-shunras-wan-emulation-for-hp-software.php
The free linux netem tool works perfectly fine in emulating WAN delays.
For example, to emulate a symmetric WAN with 300 ms delay, you can use the following commands:
Add delay to outgoing packets on eth0:
# tc qdisc add dev eth0 root netem delay 300ms
Add delay to incoming packets on eth0:
# modprobe ifb
# ip link set dev ifb0 up
# tc qdisc add dev eth0 ingress
# tc filter add dev eth0 parent ffff: protocol ip u32 match u32 0 0 flowid 1:1 action mirred egress redirect dev ifb0
# tc qdisc add dev ifb0 root netem delay 300ms
Linux has a lot of very advanced traffic control features that can be used for such purposes. For usage of the tc tool, just run a man tc on your linux machine. For details refer to:
http://lartc.org/howto/
http://linux-ip.net/articles/Traffic-Control-HOWTO/
I use WAN Emulator from XP Idea
http://www.xpidea.com/Products/tabid/53/ProductID/19/Default.aspx
It is .NET based proxy service, which sits between a client application and the real server and simulates WAN’s bandwidth and latency. I think may not be appropriate for large scale load testing, since it is a strictly software product (has buffer memory limits), although works great for me. Another good thing about it compare to Shunra for instance- it is less expensive and you don’t have to deal with the licensing. You buy it, install it and use it –no serial numbers, no use limits – nothing. …I guess those guys really rely on people’s honesty 😉
dummynet comes with every Mac, and has since 10.0
Yes, Shunra now has its VE Desktop software inside HP LoadRunner and Performance Center v9.5. You can add this capability on when you upgrade. Learn more: http://www.shunra.com/shunra_ve_desktop_for_hp_software_overview.php?keyword=VED for HP Software
There’s another free option for WAN Emulation:
http://www.dummycloud.com
Both physical and virtual appliances!!!
I’ve been using a FreeBSD based virtual appliance WAN Emulator.
They have a free version for download.
http://www.dummycloud.com
Pretty good.
Another vote for m0n0wall. It is a pre-built FreeBSD with dummynet and has a nice web interface. I run it on a Soekris net5501 box but you could use any old PC with two NICs. Just plug the box in between your client machine and the network.
We’ve tried various WAN emulates and whilst most of the free one’s do an acceptable job I found them clunky to use and not able to reproduce WAN’s accurately enough for real-world emulation.
After testing various commercial ones we decided to go with “Shamrock” (from JAR Technologies – http://www.JARTechnologies.com) mainly because its cost effective, one stop shop for emulation, load generation, stats and analysing (reports, etc.) plus it can be integrated into our test environment!! (it talks XML)
David
thank you for software
thanks
Well I’ve just found a free one on a bootable cd, waiting for it to download but looks very simple to use. Supports Jitter, Latency, bandwidth, reordering, duplication, corruption, all sorts! the lot. And you can setup different settings for different groups/IP addresses.
http://wanem.sourceforge.net/
Failed using this software – almost impossible to use…switched to a JAR Technologies range and a few mates have tried a Candelatach version. Have to humbly say that I prefer the first not sure how they are getting on? guys? want to reply?